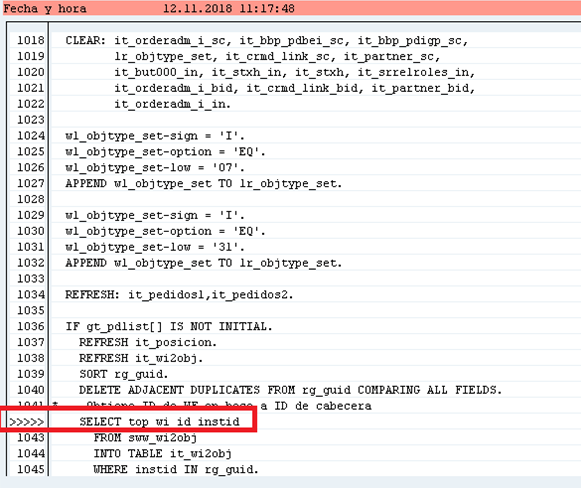
Buen día compañeros, estoy revisando un problema de rendimiento por un error de tiempo de ejecución incluso cuando el reporte se ejecuta en fondo, el error envía a la siguiente consulta:
Estaba pensando que quizá los rangos sean la causa de que esté tardando mucho porque también después entra al DELETE ADJACENT, mientras que la consulta que hice como prueba (la que tiene FOR ALL ENTRIES abajo de esa) llenando la tabla con los mismos GUID que el rango, obtiene los mismos registros sin entrar al DELETE. No estoy seguro si en el SELECT los rangos también tarden más como por estar comparando campo por campo y ver si pertenecen al rango.
No se si ya han visto casos así y me pudieran ayudar a confirmar que efectivamente los rangos afectan al rendimiento. Gracias de antemano y saludos!
Yo suelo utilizar FOR ALL ENTRIES, incluso con tablas grandes como la BKPF y no he tenido problemas de rendimiento. Lo que veo que está afectando es que no estás utilizando la llave primaria en el WHERE, ¿No tienes forma de incluir el dato?.
Podrías por favor subir la descripción breve del DUMP, ya que si bien indica que ahí en esa consulta es que se detona el DUMP, no sabemos la descripción del por que sucedió.
Al ver esa imagen, yo podría opinar que es un tema del INTO TABLE, quizás los campos que tienes en el SELECT no están de acuerdo a lo que va a la INTO TABLE, para este caso se debería revisar la estructura de la tabla interna y ver si ocupas un CORRESPONDING, lo cual es un error que comentemos en varias ocaciones.
Es por eso que te comento que lo mejor es que subas ese detalle del DUMP y será mas fácil ayudarte.
También sería genial si nos mostraras cuantos registros hay en el RANGE.
@Atilio_Josue el error tiene la descripción “Open SQL command is too big”. Como lo comenté arriba es un problema de rendimiento.
La pregunta realmente era si las consultas hechas con rangos afectan más al rendimiento que una realizada con FOR ALL ENTRIES. Tanto el rango como la tabla tiene una lista de secuencias GUID que son las que se comparan con el INSTID, el cual no es un campo llave como lo comentan @ponxo123 y @nickel_seifer, es algo que si había notado pero voy a consultarlo con el funcional para ver si podemos incluir el único que tiene esa tabla.
Usar un RANGE lo que te genera es un montón de OR’s, por lo cual si tu RANGE tiene muchos registros, te mostrará ese error.
Al menos ese error es por que es demasiado grande tal cual lo dice, por qué es grande? Por que genero algo así R1 or R2 or R3…o incluso un IN (R1, R2, R3…).
Me parece que en la ST05 podría ver cual es la SENTENCIA SQL generada al interpretar los escrito en ABAP.
No se si es global pero algunos manejadores de bases de datos solo tienen 64 KB para interpretar la sentencia SQL.
La mejor opción es usar un FAE, elimina duplicados y asegurate que no esté vacía la tabla.