Soy consultor de Business Intelligence, veo la parte backend. He presentado inconveniente con un extractor el cual me duplica o triplica a veces la información.
El extractor es 2lis_13_vditm, como ven es un extractor estándar que sirve como fuente de datos para el cubo 0SD_C03 Comercial: Resumen, lo curioso de esta inconsistencia es que sucede sólo cuando se ejecuta una carga delta. He ejecutado cargas completas de los mismos documentos de venta, pero estos no duplican, he de mencionar que la duplicidad únicamente ocurre con los valores financieros, con el tema de unidades no presenta duplicidad.
Alguien me puede explicar por que este comportamiento con las cargas delta, no sucede con todo el set de datos, son sólo algunos documentos.
Te comento que los valores en PSA me llegan hasta bien, ya que los valores que las líneas que tiene el ROCANCEL marcado están con signo contrario. Entonces hasta que llega la información al Cubo se ve duplicado o triplicado.
Mi flujo esta de la forma PSA -> Cubo
En el transaccional ECC, la información no se encuentra repetida, cada posición en la vbrp tiene su valor correcto.
Fijate que esto sucede en muy pocas ocasiones, por tal motivo nunca nos habíamos dado cuenta, pero en cantidades ya significativas se nota la diferencia. De lo que va del año únicamente con 2 documentos comerciales nos ha sucedido esto.
Por qué no intentas poner un DSO standard entre la PSA y el Cubo?, es muy posible que en el cubo te esté sumarizando los datos que ya has subido con anterioridad de los documentos 2 documentos que mencionas. Creo yo que el DSO te ayudaría a solo tomar los datos de los movimientos de los registros que “sufrieron” modificación y así solo te llegaría al cubo la información que necesitas.
Inténtalo hacer desde desarrollo, no lo apliques directamente en productivo para no tener inconvenientes.
Lo que me parece extraño es que esto sólo me sucede con las cargas Delta, y veo en el cubo la información y sólo se duplica o triplica en los valores monetarios, porque los valores en unidades llegan tal cual están en el transaccional ECC. Cuando sucede esto, hemos solucionado realizando un recálculo del documento afectado y en esa ocasión, siendo una carga completa si ingresa bien los valores.
He generado la información del cubo y en estos documentos únicamente me aparecen cargados con un ID de petición.
No sé si afecte algo en la ampliación que tengo aplicada en la cual realizo cálculos únicamente en los valores monetarios. Crees que sea posible eso?
estuve probando en QAs hace un tiempo para validar eso, pero como no pruebo con la misma magintud de datos, no me ha ocurrido este problema, como te explicaba sucede muy pocas veces, pero cuando la cantidad es demasiado grande si se refleja bien un descuadre de información.
he buscado en foros y no encuentro nada al respecto de esto. Agradezco mucho tu apoyo e interés por ayudarme.
Mira yo creo que el extractor está funcionando correctamente pues entiendo que tanto en extracción Delta como full te llega todo bien a PSA.
Lo extraño es que de PSA a Cubo en Full funciona todo bien, pero en extracción Delta te aplica duplicidad.
Ahora bien, no sé si has intentado cambiar el tipo de extracción del DTP de Full a Delta, no estoy muy seguro de como funciona ese tipo de DTP de Full con última petición (no he trabajado con este tipo), pero supongamos que el DTP te está tomando todas las peticiones en PSA y las manda al cubo y posiblemente esto cause duplicidades.
Lo que me causa un poco de confusión es esto: “hemos solucionado realizando un recálculo del documento afectado”, este recálculo lo aplicas mediante alguna rutina aplicada en la transformación, en el cubo o a nivel Bex analyzer?
Será posible que puedas poner algunas capturas para entender el comportamiento del Delta y Full en el cubo?
Y sí es posible ver los documentos afectados en ambos tipos de extracciones.
Gracias Alex por tu apoyo, podrías por favor ampliarme las configuraciones de un DTP delta, sinceramente sólo he utilizado DTPs Full con última petición. Una vez configuré un DTP Delta pero este iba a leer todo lo del PSA, si bien no inserta todo, pero leyendo cada petición se demora demasiado, pero quizá no configuré mi DTP como debería ser, o podrías por favor indicarme por qué recomiendas la utilización de un DTP delta.
Cuando hablo de un recálculo, hablo nada más de borrar y volver a cargar los documentos afectados mediante una carga completa.
Si, mira los DTP’s Delta básicamente lo que hacen es subir la última petición que se encuentre en tu PSA.
Vamos a suponer que hasta hoy tienes 7 peticiones en tu PSA y todas ellas están en el activas en el cubo, manaña llega una petición nueva Delta a tu PSA y lo que haría el DTP delta es solo llevarse esa nueva peitición, ahora bien ya tendrías 8 peticiones, pero vamos a suponer que por alguna razón regresas el DTP a full entonces el Sábado que corra tu proceso va a subir una nueva carga delta en tu PSA con lo que ya habría 9 cargas en PSA (8 anteriores y la nueva) y entonces el DTP al ser full se estaría llevando las 8 cargas ya subidas al cubo más la carga nueva, esto lo que ocasionaría es que si en esa carga delta nueva existe un movimiento para un documento que ya ha sido cargado al cubo te vaya a sumarizar o duplicar la información.
Supongo que este proceso lo corres todos los días, cierto?
En esta parte: Cuando hablo de un recálculo, hablo nada más de borrar y volver a cargar los documentos afectados mediante una carga completa.
Quiero pensar que hacer el borrado selectivo en el cubo para los documentos afectados, luego vas a infopaquete y lo corres como full y así te carga solo los valores “originales” de esos documentos, verdad?
Aqui también valdría la pena ver la posibilidad de tener un DSO como te comentaba, normalmente estos flujos de información transaccional tienden a llevar 1 esto por lo mismo de evitar duplicidades en los documentos.
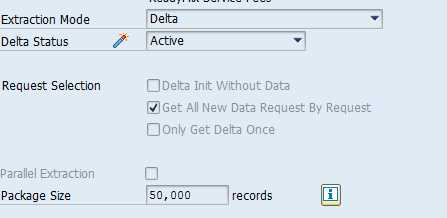
Muchas gracias por tomarte el tiempo en explicarme, es mucha molestia si me compartes una imagen de la configuración de un dtp delta para saber que checks activar y cuales no.
Te adjunto la foto de uno de los DTP’s Delta del tab de extracción, las otras 2 pestañas son información de hacía donde va a mandar información que en este caso sería tu cubo y la última pestaña es para lanzar la carga de PSA a Cubo.
si llegaras a implementar el DSO, tendrías que generar un DTP tipo delta entre tu PSA y DSO, luego un DTP delta del DSO al Cubo.
El DTP que tienes actualmente lo puedes dejar, pero no lo consideres más para tu flujo.
Muchísimas gracias Alex por tu apoyo, me servirá de mucho, una duda, el DSO se debe borrar la información cada cierto tiempo? porque sino sería como duplicar la información o no?
No es necesario borrar el DSO al contrario la función del DSO en pocas palabras es para que almacena la información a nivel transaccional (Número de documento, número de PO, etc) y al mismo tiempo tiene la función de sobreescribir la información extraída de tu PSA, por lo que no te va a causar valores duplicados, es decir que si tienes cierta cifra para un documento, cuando pase por el DSO sobreescribirá la información que ya existia para ese documento y solo agregará al cubo lo que se ha actualizado o la información nueva.
Opino que lo intentes en calidad, coméntale a tu equipo de FI o SD que genere del lado de SAP exactamente 1 o 2 documentos con los que tienes problemas en productivo y que de da ese problema para que hagas la extracción y haces las pruebas.
Te dejo este link con más información del DSO, lo explican muy bien: